Prefix-tuning과 Prompt-tuning, 그리고 임베딩 모델과 리랭커
요약
'Prefix tuning', 그리고 'soft prompt tuning'은 흔히 생각하는 프롬프트 엔지니어링과는 다르다.
흔히 생각하는 프롬프트 엔지니어링은 'hard prompt tuning'이라고 할 수 있는데, 말 그대로 프롬프트 글자 바꿔가면서 좋은 프롬프트를 찾는 것이다.
그것과는 다르게 어떠한 벡터를 인풋 프롬프트 앞에 붙여서 LLM을 인퍼런스 하면 LLM의 파라미터 자체를 튜닝하지 않고서 특정 태스크의 성능을 올릴 수 있었다고 한다!!!
이 글에서는 그런 'prefix tuning' 및 'soft prompt tuning'에 대해 간단히 알아보고, 그것들을 임베딩 모델과 리랭커에 활용한 사례를 살펴보고자 한다.
Prefix Tuning
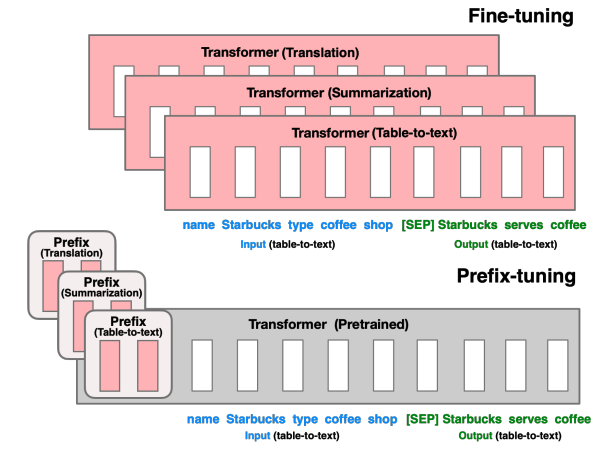
- Prefix-Tuning: Optimizing Continuous Prompts for Generation, Li & Liang et al., Stanford University, ACL 2021 (링크)
파인튜닝은 LLM 파라미터 전체, 혹은 그 일부를 학습시킨다 (LoRA 등)
prefix-tuning은 전체 LLM 파라미터를 학습시키지 않게 두고, 오직 prefix block만 학습시킨다.
이러면 학습 가능한 파라미터 수가 훨씬 적기 때문에, 적은 비용으로 학습을 진행할 수 있다.
그러면 이 prefix block은 무엇인가?
이 prefix block이라는 것은 결국 훈련 가능한 벡터이다.
그리고 이 prefix는 모든 레이어의 출력 결과물 벡터 앞에 붙는다.
즉, LM의 임베딩 레이어부터 시작해서, 그 다음 레이어, 그리고 그 다음 레이어의 결과물들에 모두 prefix vector가 붙는다.
이 prefix vector들에만 loss가 흘러 학습이 가능하고, 나머지는 frozen되어 학습이 가능하지 않다.
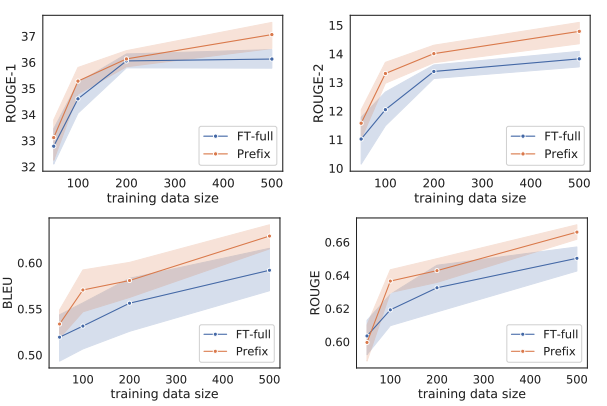
위의 두 개 그래프는 '요약' 태스크, 아래의 두 개 그래프는 'table-to-text' 태스크이다.
이 때 사용한 모델은 gpt-2와 BART이다. (chatGPT 이전의 논문이다!)
이와 같이 작은 training data만 있을 때에는 풀 파인튜닝보다 prefix-tuning의 효과가 더 좋은 것을 볼 수 있다.
Prompt Tuning (Soft)
- The Power of Scale for Parameter-Efficient Prompt Tuning, Lester et al., Google Research, EMNLP 2021 (링크)
Prefix-Tuning이 모든 레이어의 출력값 앞에 학습 가능한 prefix vector를 붙였다면, prompt tuning은 딱 '인풋 프롬프트' 앞에 prefix vector를 붙여준다.
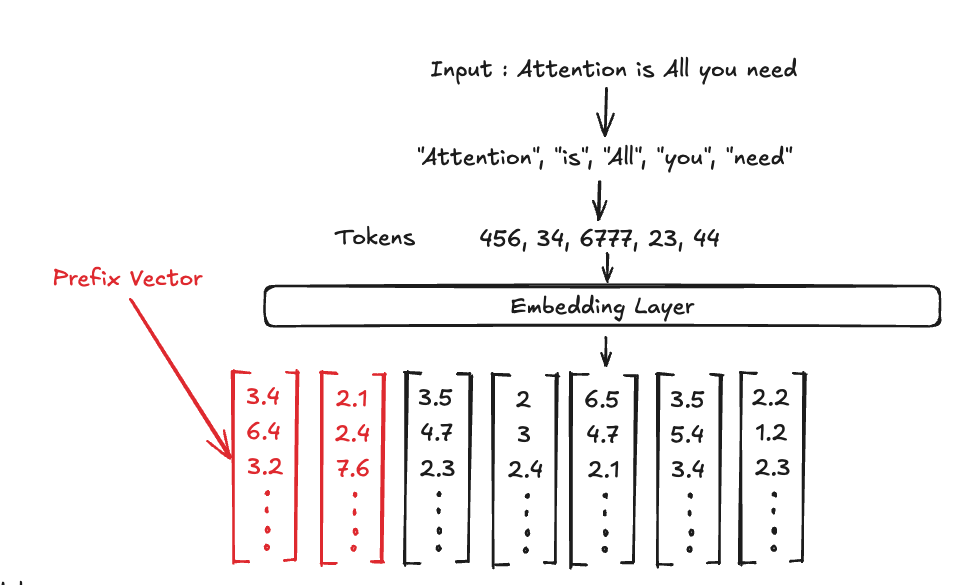
이 prefix vector는 모델의 임베딩 레이어를 지난 그 '임베딩 벡터'와 길이가 같기 때문에, 어떤 특별한 토큰을 만들었다~ 라고도 볼 수 있다.
그러니깐, 실제로는 특별한 토큰을 만든 것은 아니다.
다만, 어떤 특정한 토큰이 특정한 임베딩 벡터로 변환되는 임베딩 레이어의 특성을 생각해보자.
우리가 만든 것은, 임베딩 레이어와 정확히 똑같은 차원의 벡터 여러개를, 모든 LLM의 인풋 앞에다가 붙여주는 것이다.
그러면 실제로는 존재하지 않지만, 어떤 특별한 토큰들을 LLM 앞에 붙여준다고 할 수 있다. 이해가 되는가?
이런 Prefix Vector는 Soft Prompt라고 부르기도 한다.
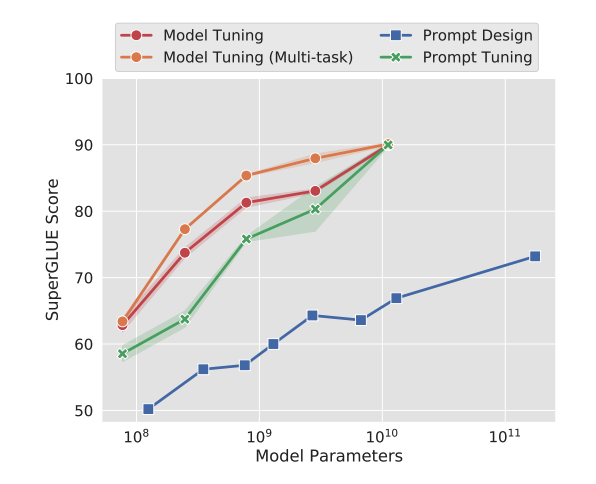
SuperGLUE는 자연어 이해 능력을 측정하는, 조금 오래된 벤치마크이다.
해당 논문은 T5 모델을 실험에 사용했다.
보면 알 수 있다시피, 흔히 말하는 프롬프트 엔지니어링은 파란색, prompt tuning은 초록색, 빨간색과 주황색은 모델의 파라미터를 직접 수정하는 것이다.
모델의 파라미터가 커질수록 프롬프트 튜닝이 효과적으로 작동하는 것을 볼 수 있다.
아마... LLM에서도 효과적으로 작동하지 않을까? (DefensiveToken 과 같은 사례를 보면 효과적인 작동이 가능한 듯 싶다)
이것을 임베딩 모델 튜닝에도 써보자!
- Prompt Tuning Can Simply Adapt Large Language Models to Text Encoders, Zhao et al., University of Tokyo, Proceedings of RepL4NLP-2025 (링크)
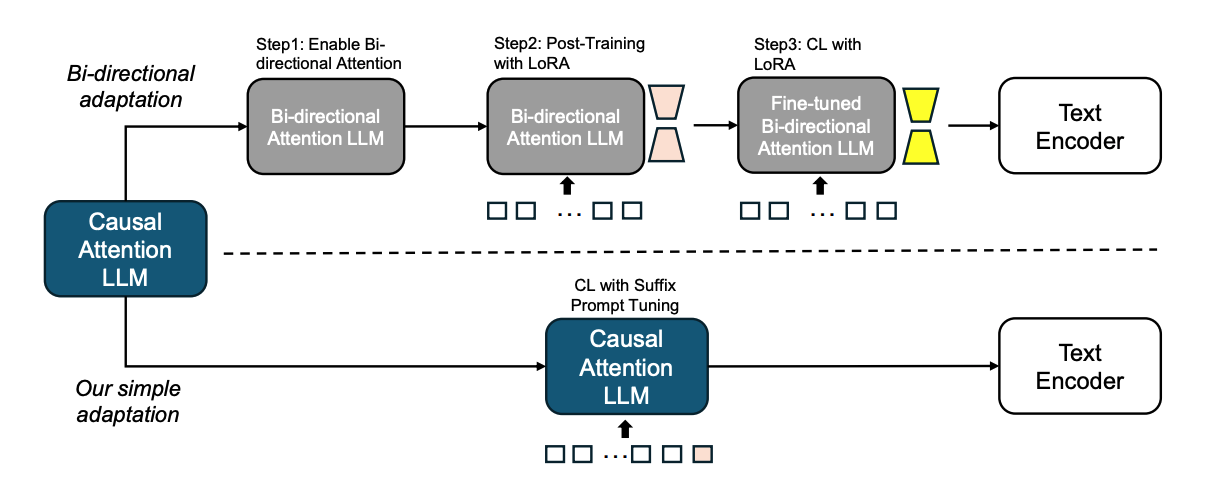
원래 LLM을 어떻게 임베딩 모델 (Text Encoder)로 만들어 썼는가?
먼저 masked self-attention에서 mask를 해제해서 bi-directional LLM으로 만들었다.
그 다음 LoRA를 통해 다시 훈련을 수행한다. (즉 일부 레이어만 bi-directional layer로 만들어도 괜찮다는 뜻)이 때는 next-token prediction으로 훈련을 수행한다.
그리고서 Contrastive Learning을 이용해 또 다시 파인튜닝을 한다.
자, 이제 'Suffix Prompt Tuning' 딸깍으로 임베딩 모델을 성공적으로 훈련시켜보자.
일단 앞에서 나온 prompt tuning 기법을 똑같이 써먹을 것인데, 이번에는 앞이 아닌 뒤에 soft prompt를 붙여준다.
기존 LLM-based 임베딩 모델과 마찬가지로 마지막 토큰의 output hidden state를 임베딩 벡터로 사용하고, contrastive loss 중 하나인 InfoNCE loss를 사용해서 soft prompt를 훈련했다.
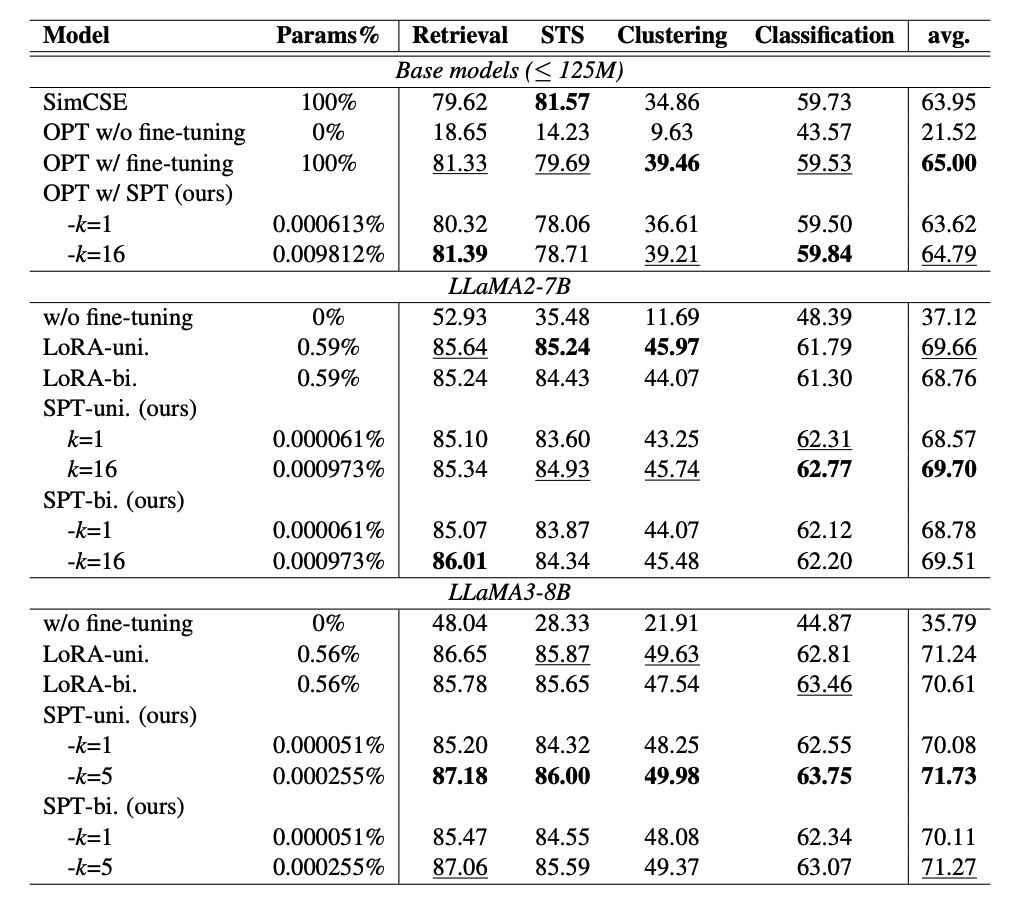
SPT-uni는 기본적인 suffix prompt tuning이고, SPT-bi는 bi-directional LLM으로 일부 전환 후 next token prediction으로 훈련을 한 상황이라고 한다. (LoRA-bi + SPT)
결과를 보면 알다시피 네 가지 임베딩 모델 태스크에 있어서 SPT-uni에서 토큰이 16개인 경우 Llama2-7B와 Llama3-8B 모두에서 가장 높은 성능을 차지했다!!
그러면 리랭커에도 써보자!!
- Passage-specific Prompt Tuning for Passage Reranking in Question Answering with Large Language Models, Wu et al., Santa Clara University, SIGIR 2024 (링크)
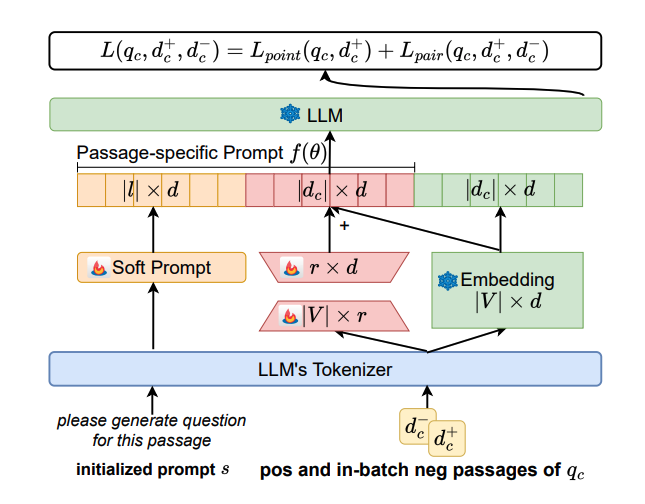
기본적으로 이 방법은 query-pointwise 방법이다. 단락을 주고 예상되는 질문을 생성하도록 한다. 원래 질문이 생성될 확률이 relevancy score가 된다.
위의 그림을 보면서 설명해보자.
노란색은 'please generate question for this passage'라는 프롬프트로부터 initialize 된 훈련 가능한 soft prompt이다. 이것은 passage에 관계 없이 들어간다.
그리고 빨간색은 passage를 특정 벡터로 바꾸는, LLM의 임베딩 레이어와 같은 역할을 한다고 보면 된다.
다만 LoRA처럼 더 적은 파라미터 훈련을 위하여 마치 Auto Encoder를 떠올리는 (혹은 UNet?) 모양의 bottleneck이 있는 네트워크로 임베딩 레이어를 만들었다.
이것 역시 훈련되며, 이 부분은 입력 passage에 따라서 달라지게 된다.
마지막으로 초록색은 원래 LLM의 임베딩 레이어이며 훈련되지 않는다.
이제 세 벡터들이 모두 합쳐진 것이 LLM의 인풋으로 들어가고, 원래 query가 생성될 확률을 relevancy score로 한다.
Loss는 두 가지 loss를 주는데, positive 단락에서 query를 생성할 확률을 높이는 loss.
그리고 "(negative 단락에서 query를 생성할 확률) - (positive 단락에서 query를 생성할 확률)"을 최대화하는 loss이다.
이 두가지 loss를 더해서 soft prompt들을 훈련하게 된다!
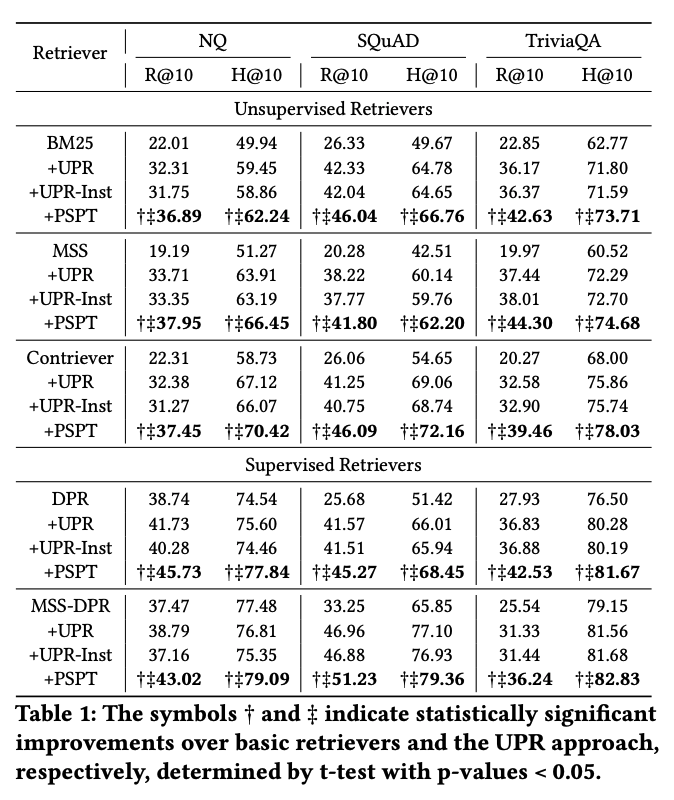
베이스라인으로는 UPR Reranker를 사용했다.
NQ, SQuAD, TriviaQA의 ODQA 데이터셋에서 기존 리랭커보다 좋은 성능을 보여준다..!
근데 아쉬운 점은 LLM 기반 리랭커 (RankGPT 등 Listwise)와의 비교는 없다.
결론
여러 태스크에 대해 prompt tuning을 쉽게 할 수 있는 라이브러리가 있었으면 좋겠다. 하나 만들어볼까?